Monitoring

Key Concepts¶
Utilizing AWS CloudWatch dashboards enables centralized monitoring of API Gateway, Lambda functions, and DynamoDB, providing real-time insights into their performance and operational health. By aggregating metrics, logs, and alarms, CloudWatch facilitates swift issue diagnosis and analysis across your serverless applications. Additionally, setting up alarms ensures immediate alerts during anomalous activities, enabling proactive issue mitigation.
Service Architecture¶
flowchart LR
subgraph AWS["AWS Cloud"]
subgraph APIGW["API Gateway"]
REST["REST API<br/>POST /api/orders<br/>GET /api/orders/{id}<br/>DELETE /api/orders/{id}"]
end
subgraph Security["Security (Production)"]
WAF["WAF WebACL<br/>AWS Managed Rules"]
end
subgraph Compute["Compute"]
CREATE["Create Order<br/>Lambda Function"]
GET["Get Order<br/>Lambda Function"]
DELETE["Delete Order<br/>Lambda Function"]
LAYER["Lambda Layer<br/>Common Dependencies"]
end
subgraph Config["Configuration"]
APPCONFIG["AppConfig<br/>Feature Flags"]
end
subgraph Storage["Storage"]
DDB[("DynamoDB<br/>Orders Table")]
IDEMPOTENCY[("DynamoDB<br/>Idempotency Table")]
end
end
CLIENT((Client)) --> WAF
WAF --> REST
REST --> CREATE
REST --> GET
REST --> DELETE
CREATE --> LAYER
GET --> LAYER
DELETE --> LAYER
CREATE --> APPCONFIG
CREATE --> DDB
CREATE --> IDEMPOTENCY
GET --> DDB
DELETE --> DDB
style CLIENT fill:#f9f,stroke:#333
style WAF fill:#ff6b6b,stroke:#333
style REST fill:#4ecdc4,stroke:#333
style CREATE fill:#ffe66d,stroke:#333
style GET fill:#ffe66d,stroke:#333
style DELETE fill:#ffe66d,stroke:#333
style LAYER fill:#ffe66d,stroke:#333
style APPCONFIG fill:#95e1d3,stroke:#333
style DDB fill:#4a90d9,stroke:#333
style IDEMPOTENCY fill:#4a90d9,stroke:#333Click diagram to zoom
The goal is to monitor the service API gateway, Lambda function, and DynamoDB tables and ensure everything is in order.
In addition, we want to visualize service KPI metrics.
Monitoring Dashboards¶
We will define two dashboards:
- High level
- Low level
Each dashboard has its usage and tailors different personas' usage.
High Level Dashboard¶
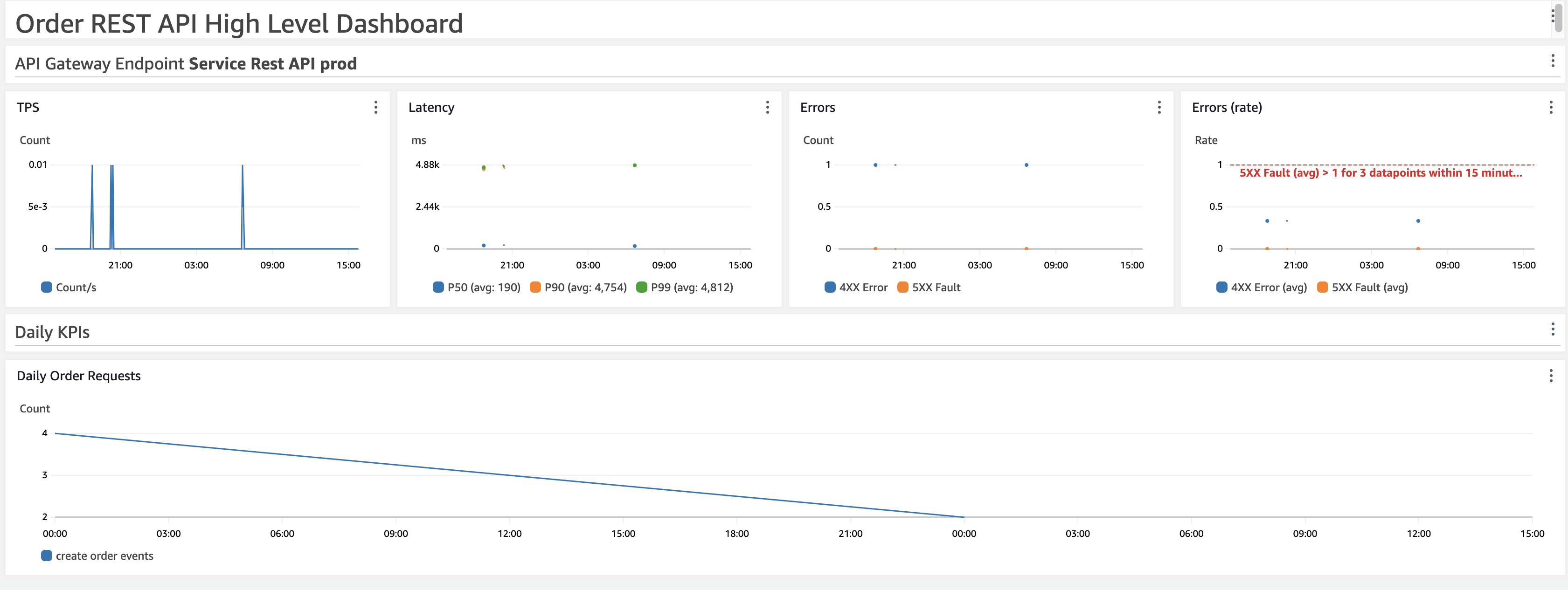
This dashboard is designed to be an executive overview of the service.
Total API gateway metrics provide information on the performance and error rate of the service.
KPI metrics are included in the bottom part as well.
Personas that use this dashboard: SRE, developers, and product teams (KPIs)
Low Level Dashboard¶
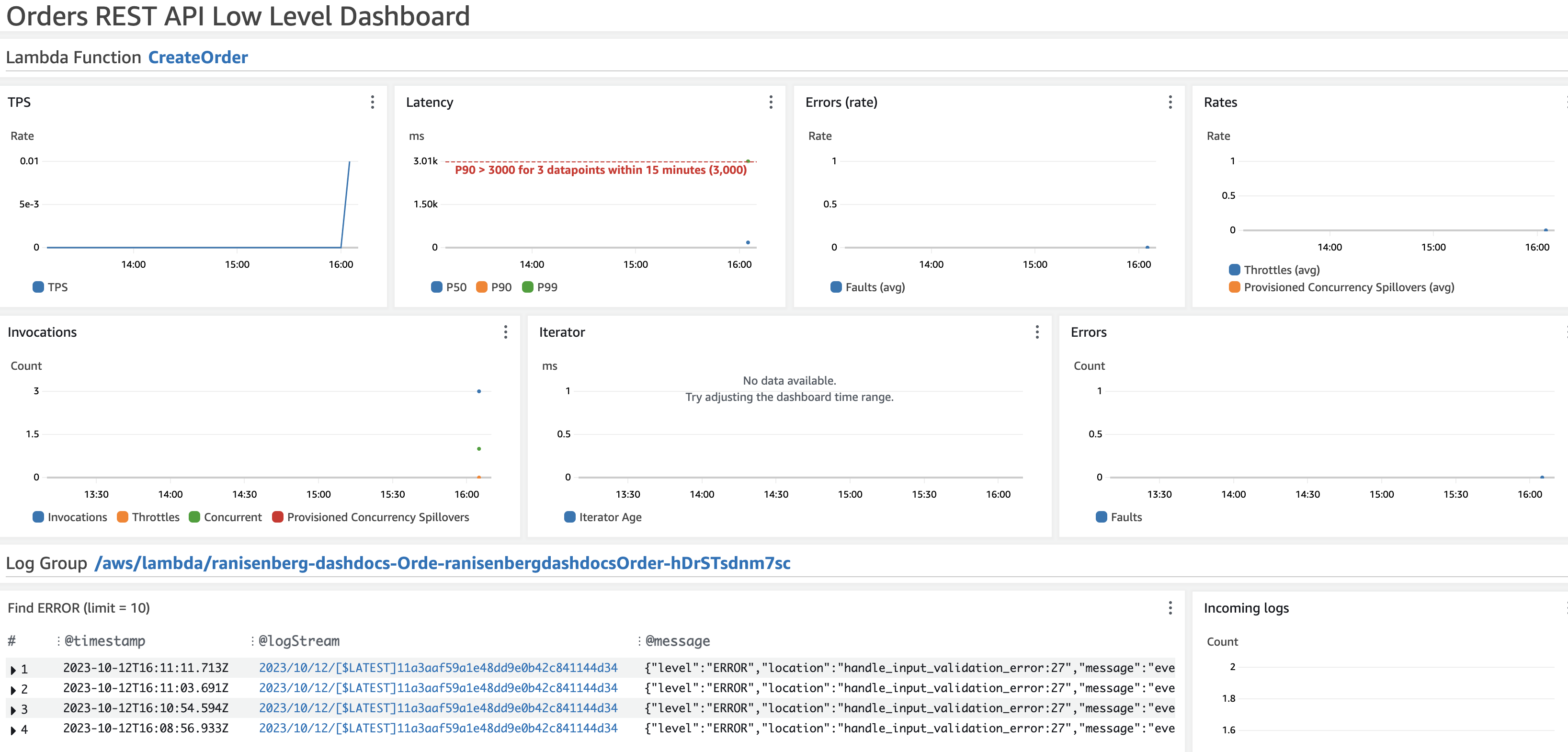
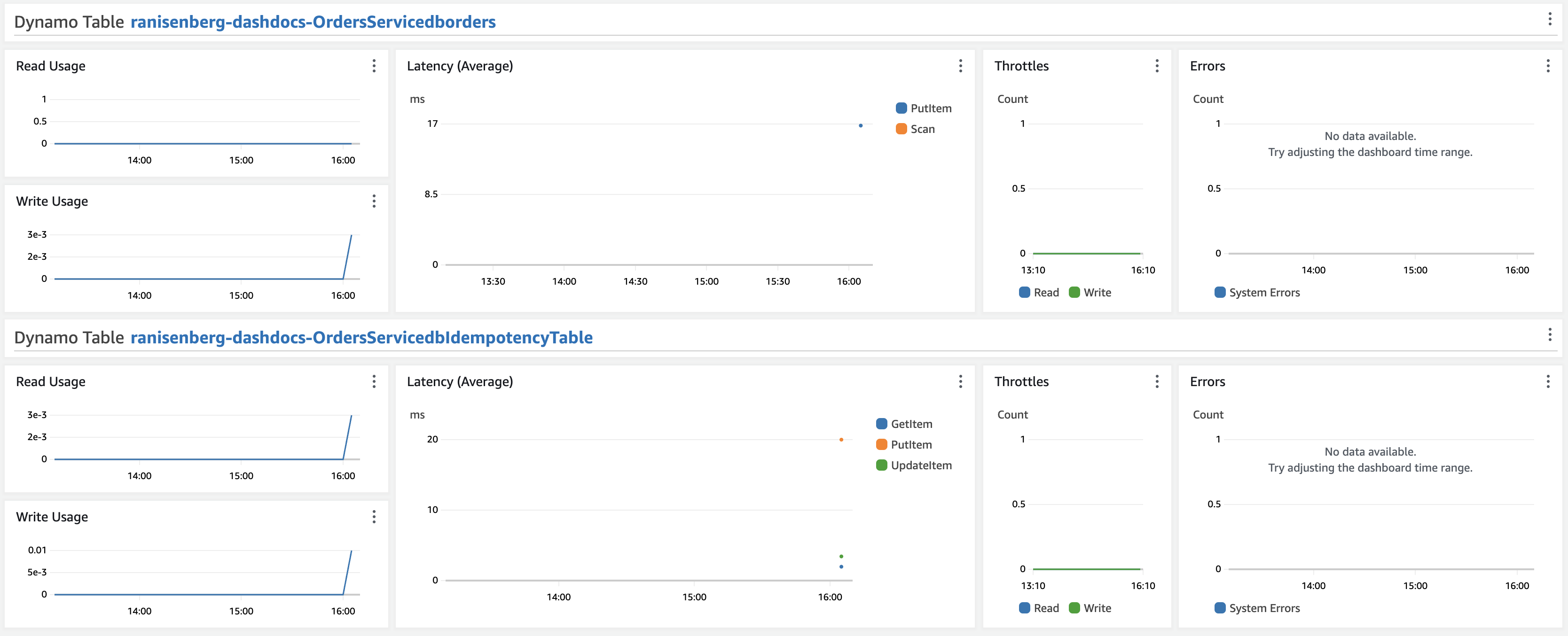
It is aimed at a deep dive into all the service's resources. Requires an understanding of the service architecture and its moving parts.
The dashboard provides the Lambda function's metrics for latency, errors, throttles, provisioned concurrency, and total invocations.
In addition, a CloudWatch logs widget shows only 'error' logs from the Lambda function.
As for DynamoDB tables, we have the primary database and the idempotency table for usage, operation latency, errors, and throttles.
Personas that use this dashboard: developers, SREs.
Alarms¶
Having visibility and information is one thing, but being proactive and knowing beforehand that a significant error is looming is another. A CloudWatch
Alarm is an automated notification tool within AWS CloudWatch that triggers alerts based on user-defined thresholds, enabling users to identify and
respond to operational issues, breaches, or anomalies in AWS resources by monitoring specified metrics over a designated period.
In this dashboard, you will find an example of two types of alarms:
- Alarm for performance threshold monitoring
- Alarm for error rate threshold monitoring
For latency-related issues, we define the following alarm:
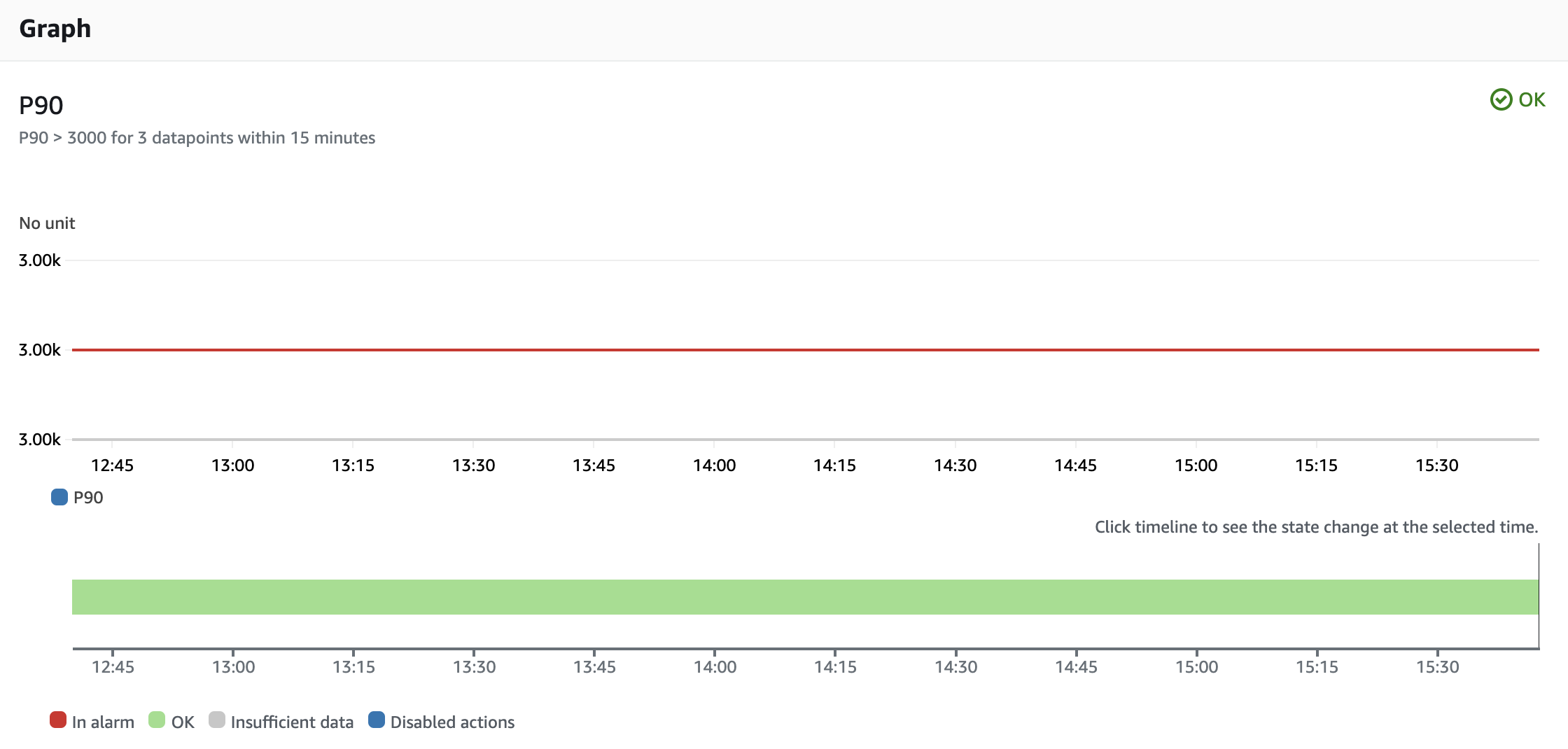
For P90, P50 metrics, follow this explanation.
For internal server errors rate, we define the following alarm:
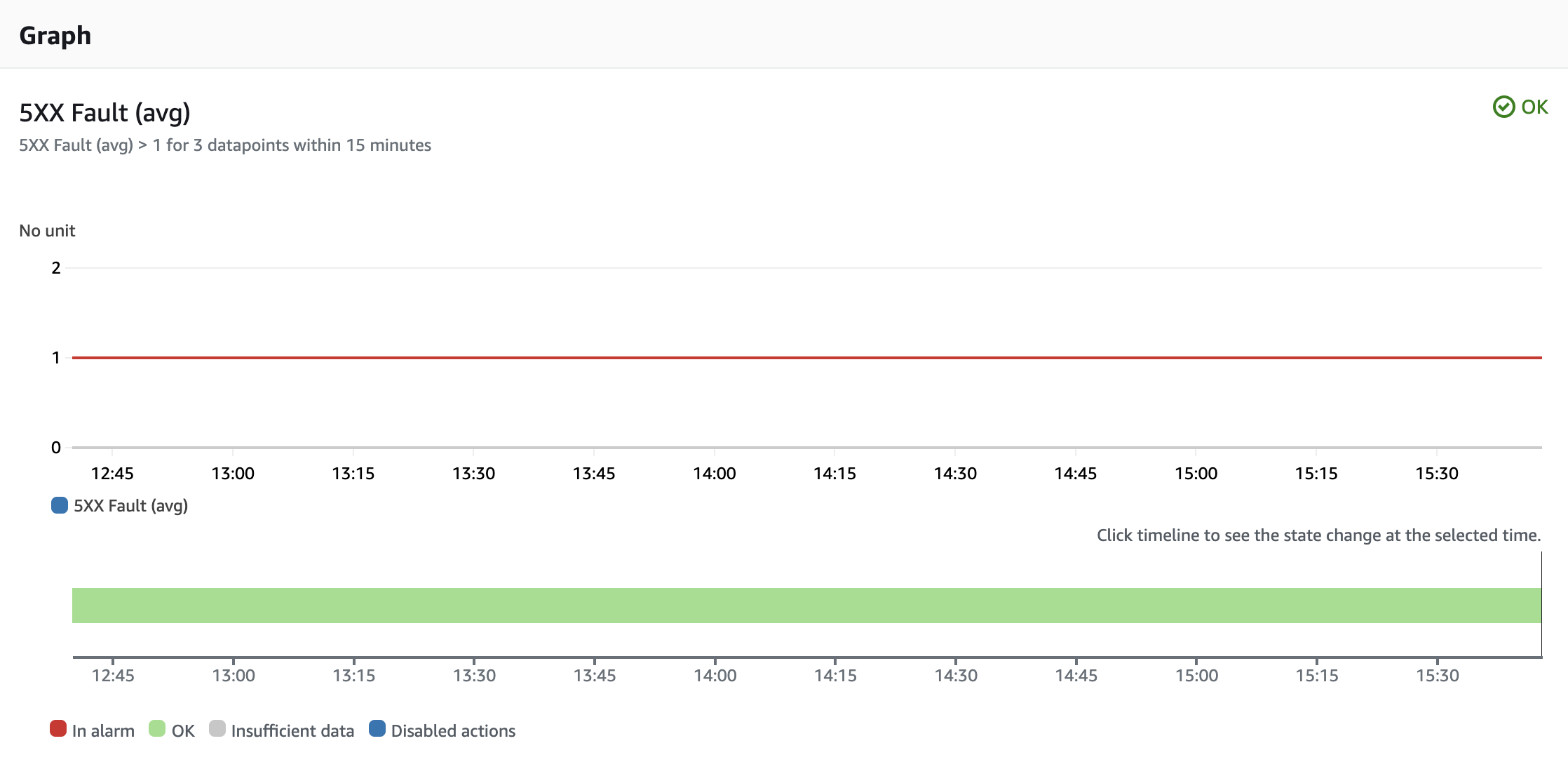
Actions¶
Alarms are of no use unless they have an action. We have configured the alarms to send an SNS notification to a new SNS topic. From there, you can connect any subscription - HTTPS/SMS/Email, etc. to notify your teams with the alarm details.
CDK Reference¶
We use the open-source cdk-monitoring-constructs.
You can find the monitoring CDK construct on GitHub.
Further Reading¶
If you wish to learn more about this concept and go over details on the CDK code, check out my blog post.